VirES for (not only) Swarm - 2023 update
It has been a while since the last blog post about VirES for Swarm, but don't let that make you think the level of activity has dropped. The service has moved from strength to strength and enjoys a continually growing number of users, a steady addition of features and datasets, and excitement about the future possibilities.
Some of the highlights include full adoption of the Heliophysics API (opens new window) (HAPI), optimised provision of magnetic model calculations, and better support for user-driven on-demand processing of data through community-sourced Python packages supported by the VRE (JupyterHub).
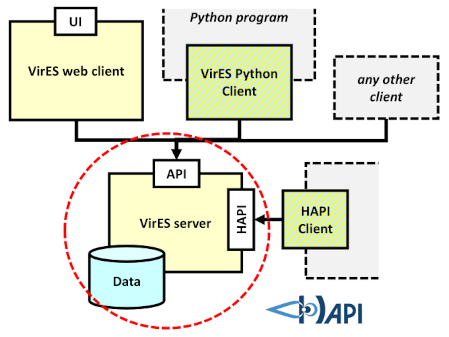
HAPI has been added to VirES as an extra access mechanism, covering all the relevant datasets within VirES as well as providing magnetic model predictions (which are non-trivial for a user to independently calculate). This adds to the burgeoning ecosystem of HAPI data services and makes for a more seamless integration of Swarm products within external systems, backed by a fully open and interoperable ethos. We expect this to greatly increase the availability of Swarm products (a key goal for ESA), while keeping all the opportunities of the full VirES API for more specific services.
Outside the work of EOX, the scientific community behind Swarm is thriving and continues to improve and expand the data product portfolio, now with cleaner documentation through the new Swarm data handbook (opens new window). This handbook is interconnected with the VirES service with links to both the VirES GUI for immediate visualisation and VRE notebooks for Python-based guides, which increases the discoverability of these services and makes it easier for researchers to find relevant information and jump into analysis.
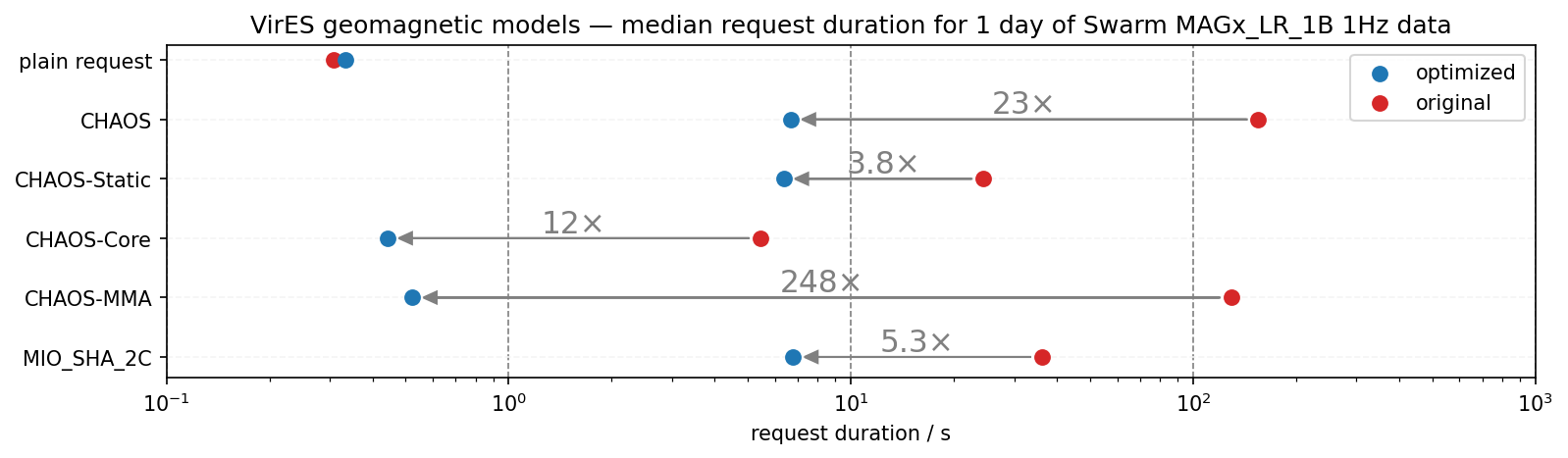
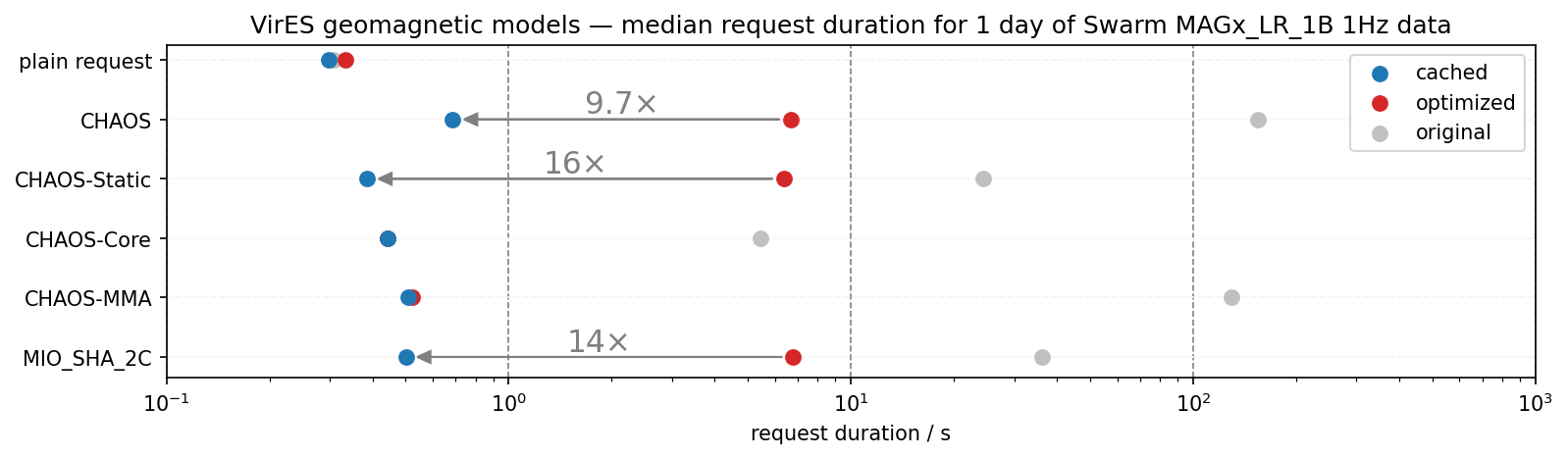
Geomagnetic models in VirES (opens new window) have now had a radical improvement, with both heavily optimised calculations and caching of values. Accessing these predictions alongside the satellite and ground measurements (a common task for users of such data) now requires no significant additional processing time for most applications.
This is relevant for our next point: the provision of data from a new "FAST" processing chain from Swarm. In order to support space weather monitoring from Swarm, ESA are now providing a variant of the data (with less guarantee on data quality) that is delivered as soon as possible from the spacecraft. Work has already been under way to integrate this within VirES so these data will be available imminently.
With the advent of the FAST processing chain, this raises the issue of what to do for provisioning of the higher-level derived products. With the complex and distributed (across institutions) nature of the Swarm processing system, and the ephemeral nature of FAST data (only being relevant for a short time), it makes little sense to duplicate the effort of processing and storing FAST variants of derived datasets.
This is connected with an ongoing discussion about providing services rather than products, where such derived data could instead be processed on-demand rather than stored forever. As well as the concept of on-demand processing, there is a need for toolboxes, which enable researchers to configurably apply a complex algorithm and more easily analyse the results. These toolboxes must be built by the researchers themselves to ensure the end result is useful and correct, while there is an important role of research software engineers to improve the overall design and sustainability.
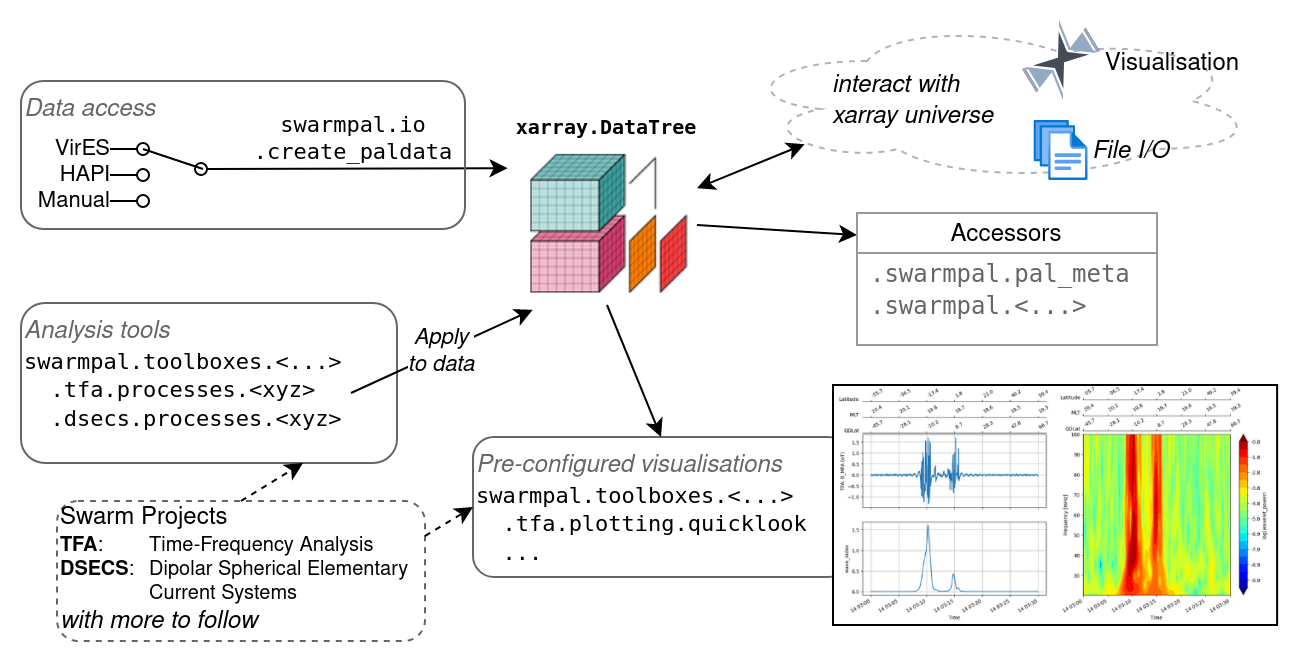
This is being tackled with the new SwarmPAL package (opens new window), a first version of which is already available within the VRE, whose success rests on VirES providing the powerful data access capabilities.
Python environments are complex and data science workflows are often fragile and loaded with details about specific datasets. The Swarm Notebooks resource (opens new window) continues to work on these two fronts. By exposing a range of data access recipes and giving examples of using community-developed Python packages, backed by the VRE providing the execution environment, we make these workflows more discoverable and reproducible. They are made more reliable by the application of Continuous Integration (using a combination of nbmake and jupyterbook) to systematically verify them, effectively acting as an integration test of the recipe, the software environment, the VirES service, and the data themselves.
It can be seen that the past few years of the VirES service has been characterised by a two-way interaction in the development, between EOX and the user community. We expect this trend to continue, with further software systems plugging into VirES, which we find as an increasingly important reference point within a more complex ecosystem.
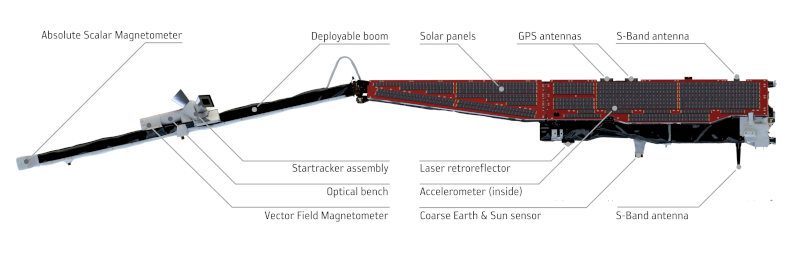
Title image: Swarm instruments (side view) Ⓒ2012 ESA/AOES Medialab