
Cloud Workspaces for Earth Observation data processing - from Ideas to Solutions
The importance of Earth Observation (EO) data for large scale and monitoring tasks has been recognized in many business domains. The way EO data is consumed has become even more demanding, starting with EO data visualization tasks (want to observe a Sahara dust event in your browser?) to large scale data processing workflows to produce analysis ready data (e.g. the EOxCloudless product in the context of the Common Agricultural Policy).
The last months brought several initiatives like RACE (Rapid Action Coronavirus Earth observation), showcasing how satellite data can help to monitor the situation linked with the Corona pandemic, by providing access to various environmental, economic and social indicators to measure the impact of the lockdown. These indicators were provided in an unprecedented collaboration effort between ESA, scientific teams and individual contributors who contributed new unique ideas. These were selected and added from the Euro Data Cube Custom Script Contest (opens new window) and the subsequent RACE upscaling competition (opens new window).
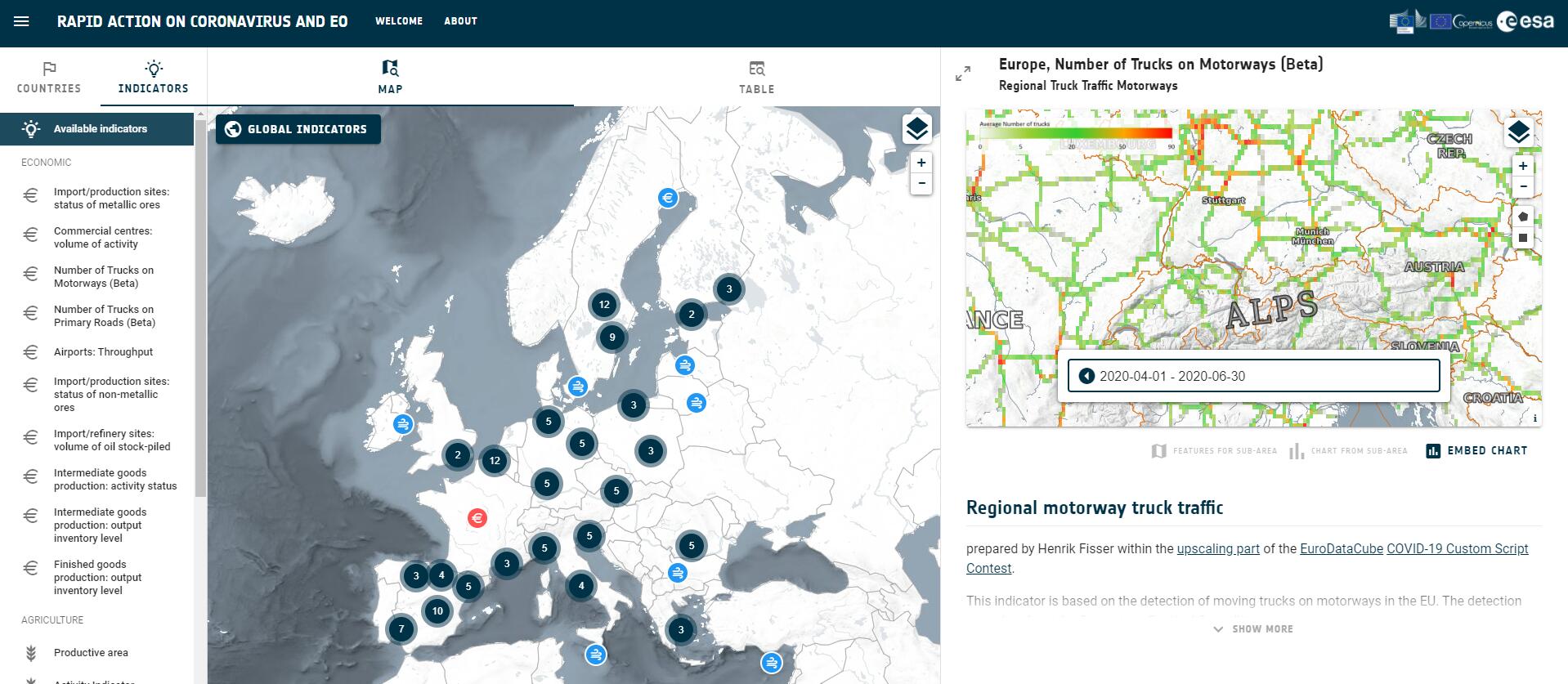 Europe-wide number of trucks on motorways indicator on RACE dashboard (opens new window)
Europe-wide number of trucks on motorways indicator on RACE dashboard (opens new window)
We at EOX got the opportunity to feature the winner of this competition, Henrik Fisser (opens new window) with his submission "Sensing trade from space with Sentinel-2 (opens new window)" during one of our Euro Data Cube ESA EO Φ-WEEK 2020 side events. (opens new window) In addition, Sinergise (opens new window), our consortium partner in the Euro Data Cube project (opens new window), published a great blog post (opens new window) summarizing the results and achievements of the EO innovations.
While the authors behind these ideas got access to (free and commercial) EO data sources and the necessary resources on the Euro Data Cube to process them, they still had to face the same challenges with their EO processing tasks as anyone else working on large scale EO workloads from detailed EO data timeseries data analysis, Machine Learning to Deep Learning and A.I.:
- How to handle the huge amount of (not always analysis-ready) data - input EO sources, reference data, intermediate caches, final result output?
- How to apply the different analysis and processing methodologies on the data - both interactive for exploration and systematic for large scale?
In a previous blog post we explained the need of an elastic and scalable compute layer with various storage options close to EO data for any kind of processing workloads. We also introduced the EDC EOxHub Workspace (opens new window) services, making this concept of ready-made cloud infrastructure real and publicly available to the contest participants for their large scale contributions and also to you, dear reader of this blog, offered in self-service mode on the EDC marketplace (opens new window).

So what can you use from our offer for your EO workloads:
- a JupyterLab (opens new window) installation, fully managed for you in your private cloud workspace, as your interactive development and exploration tool,
- running your defined EO workloads in the cloud, leveraging your selected flavor of compute (CPU/GPU, memory size) and network resources,
- with a prepared base environment (the EDC kernel (opens new window)) managed by us with commonly used data analysis and EO processing tools, regularly updated to the latest library versions, versioned itself to foster reproducibility, and extensible (opens new window) to support the needs for additional tools and libraries,
- with a persistent file system to manage the notebooks and the code defining your EO workloads,
- (optional) with mounted object storage, to store huge amounts of data (e.g. staged EO input data or final result data) in a cost effective way and
- (optional) with attached block storage, to serve as high-throughput cache layer for intermediate processing results.
But as soon as you consider your EO workloads as "ready" and you prepare them for headless invocation (see preparatory steps here (opens new window)), you get even more possibilities:
- directly invoke your notebooks via API calls (opens new window), with the same environment prepared as via interactive invocation through JupyterLab, to ensure the same the behavior (and the same results) for your EO processing tasks,
- follow the headless execution path in an automatically generated result notebook, providing the full execution trace and also necessary information for troubleshooting if something went wrong,
- automate the invocation based on a time-based job scheduler (not available in self-service mode yet),
- understand the behavior of your processes, as various runtime metrics are exposed through your personal dashboard.
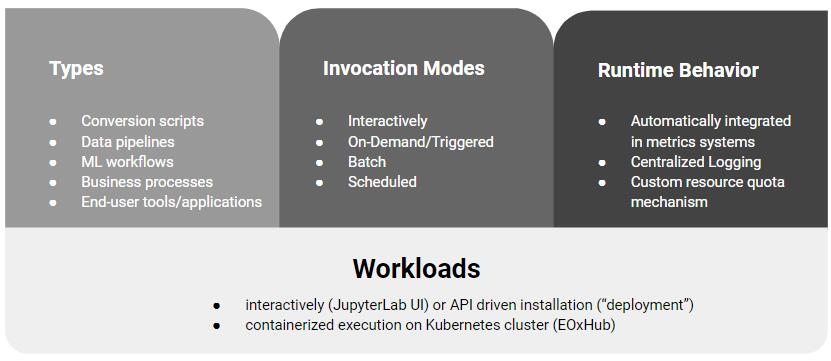
Here at EOX we are already using the underlying technology of EDC EOxHub Workspaces for our own (opens new window) and customer-driven (opens new window) EO workloads. We are happy that we can foster the processing of several of the indicators as showcased on the European (opens new window) (ESA) and Worldwide (opens new window) (ESA, NASA, JAXA) dashboard. Offering on-demand functionality on top of powerful cloud infrastructure e.g. with GPU instances for the training and inference of Machine Learning models using PyTorch (opens new window) or TensorFlow (opens new window).
Our Cloud Workspace services are constantly evolving and more are being developed as you read this, but we have good news for you, there's no need to wait! You can start at the Euro Data Cube (opens new window) today.